Mosaic AI - Provides unified tooling to build deploy and monitor AI and ML solutions
Large Language Models - Machine learning models that are very effective at performing language-related tasks such as translation, answering questions, chat and content summarization, as well as content and code generation. LLMs distill value from huge datasets and make that "learning" accessible out of the box. Databricks makes it simple to access these LLMs to integrate into your workflows as well as platform capabilities to augment, fine-tune and pre-train your own LLMs using your own data for better domain performance.
Retrieval Augmented Generation (RAG)
- A generative AI application pattern that finds data/documents relevant to a question or task and provides them as context for the large language model (LLM) to give more accurate responses.
- Databricks has a suite of RAG tools that helps you combine and optimize all aspects of the RAG process such as data preparation, retrieval models, language models (either SaaS or open source), ranking and post-processing pipelines, prompt engineering, and training models on custom enterprise data.
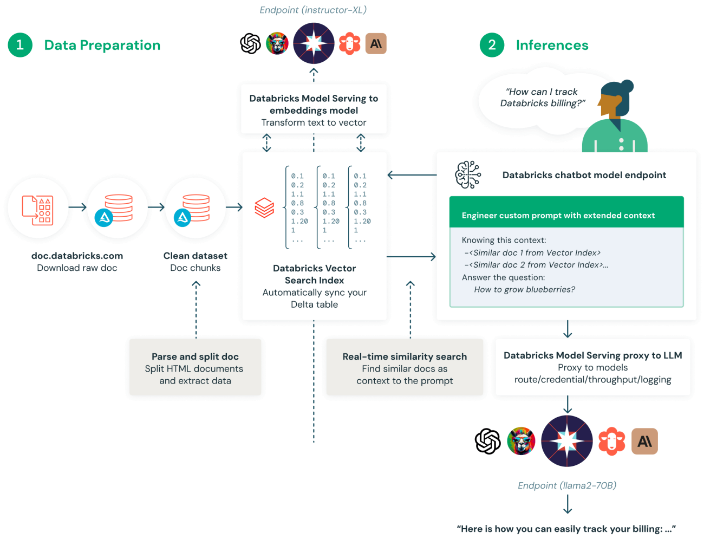
- Access to open source and proprietary SaaS models : with databricks, you can deplo, monitor, govern and query any generative AI model. All popular models like LangChain, Llama 2, MPT and BGE, and models on Azure OpenAI, Amazon Bedrock, Amazon SageMaker and Anthropic can be managed and governed in Model Serving, making it easy to experiment with and productinize models to find the best candidate for your RAG application.
- Automated real-time pipelines for any type of data : Databricks natively supports serving and indexing your data for online retrieval. For unstructured data (text, images and video), vector search automatically indexes and serves data, making them accessible for RAG applications without needing to create separate data pipelines. Under the hood, Vector search manages failures, handles retries and optimizes batch sizes to provide you with the best performance, throughput and cost. For structured data, Feature and Function Serving provides millisecond-scale queries of contextual data, such as user or account data, that enterprises often want to inject into prompts in order to customize them based on user information.
- Move RAG applications quickly to production : Databricks makes it easy to deploy, govern, query and monitor large language models fine-tuned or pre-deployed by Databricks or from any other model provider. Databricks Model Serving will handle automated container build and infrastructure management to reduce maintenance costs and speed up deployment.
- Governance built in : Databricks has security, governance and monitoring built in. RAG applications will have fine-grained access controls on data and models. You can set rate limits and track lineage across all models. This ensures the RAG application won't expose confidential data to users who shouldn't have access.
- Ensure quality and safety in production : To meet the standard of quality required for customer-facing applications, AI output must be accurate, current, aware of your enterprise context, and safe. Databricksmakes it easy to understand model quailty with LLM automated evaluation, improving the helpfulness, relevance and accuracy of RAG chatbot responses. Lakehose Monitoring automatically scans application outputs for toxic, halluciated or otherwise unsafe content. This data can then feed dashboards, alerts or other downstream data pipelines for subsequent actioning.
Generative AI Architecture Patterns
- Start building your generative AI solution
- There are four architectural patterns to consider when building a large language model (LLM) solution.
- Databricks is the only provider that lets you build high-quality solutions at low cost across all four generative AI architectural patterns.

- Prompt engineering is the practice of customizing prompts to elicit better responses without changing the underlying model. Prompt engineering is easy in Databricks by finding avaliable models in the Marketplace (including popular open source models such as Llama2 and MPT), serving models behind an endpoint in Model serving, and evaluting prompts in an easy-to-use UI with Playground or MLflow
- Retrieval Augmented Generation (RAG) finds data/documents that are relevant to a question or task and provides them as context fo the LLM to give more relevant responses. Databricks has a suite of RAG tools that helps you combine and optimize all aspects of the RAG process such as data preparation, retrieval models, language models (either SaaS or open source), ranking and post-processing pipelines, prompt engineering, and training models on custom enterprise data.
- Fine-tuning adapts an existing general-purpose LLM model by doing additional training using your organization's IP with your data. Databricks fine-tuning lets you do this easily by allowing you to start with your preferred LLM model - including curated models by databricks such as MPT-30B, Llama2 and BGE - and giving you the ability to do further training on new datasets.
- Pretraining is the practice of building a new LLM model from scratch to ensure the foundational knowledge of the model is tailored to your specific domain. By training on your organization's IP with your data, it creates a customized model that is uniquely differentiated. Databricks Mosaic AI Pretraining is an optimized training solution that can build new multibillion parameter LLMs in days with up to 10x lower training costs.
- Crossing the best pattern : These architectural patterns are not mutually exclusive. Rather, then can (and should) be combined to take advantage of the strengths of each in different generative AI deployments. Databricks is the only provider that enables all four generative AI architectural patterns, ensuring you have the most options and can evolve as your business requirements demand.
Vector Search - A highly performant vector databse with governance built-in
- Unlock generative AI's full potential with Databricks Vector Search
- Vector Search is a serverless vector database seamlessly integrated in the Data Intelligence Platform
- Unlike other databses, Databricks Vector Search supports automatic data synchronization from source to index, eliminating complex and costly pipeline maintenance. It leverages the same security and data governance tools organizations have already built for peace of mind. With its serverless design, Databricks Vector Search easily scales to support billions of embeddings and thousands of real-time queries per second.
- Built for retrieval augmented generation (RAG) : Databricks Vector Search is purpose-built for customers to augment their large language models (LLMs) with enterprise data. Specifically designed for retrieval augmented generation (RAG) applications, Databricks Vector Search delivers similarity search results, enriching LLM queries with context and domain knowledge, and improving accuracy and quality of results.
- Built-in governance : The unified interface defines policies on data, with fine-grained access control on embeddings. With built-in integration to Unity Catalog, Vector Search shows data lineage and tracking automatically without the need for additional tools or security policies. This ensures LLM models won't expose confidential data to users who shouldn't have access.
- Fast query performance : Automatically scales out to handle billions of embeddings in an index and thousands of queries per second. It shows up to 5x faster performance than other leading vector databases on up to 1 million OpenAI embiedding datasets.
Feature engineering
- Feature Store : The first feature store co-designed with a data platform and MLOps framework
- Provide data teams with the ability to create new features, explore and resuse existing ones, publish features to low-latency online stores, build training data sets and retrieve feature values for batch inference.
- Features as reusable assets : Feature Registry provides a searchable record of all features, their associated definition, source data, and their consumers, eliminating considerable rework across teams. Data Scientists, analysts and ML engineers can search for features based on the consumed raw data and either use features directly or fork existing features.
- Consistent features for training and serving : Feature Provider serves the features in two modes. Batch mode provides features at high throughput for training ML models or batch inference. Online mode provides features at low latency for serving ML models or for the consumption of the same features in BI applications. Features used in model training are automatically tracked with the model and, during model inference, the model itself retrieves them directly from the feature store.
- Secure features with built-in governance : Feature store integrations provide the full lineage of the data used to compute features. Features have associated ACLs to ensure the right level of security. Integration with MLflow ensures that the features are stored alongside the ML models, eliminating drift between training and serving time.
Model Serving - Unified deployment and governance for all AI models
- Introduction : databricks Model Serving is a unified service for deploying, governing, querying and monitoring models fine-tuned or pre-deployed by Databricks like Llama 2, Mosaic ML MPT or BGE, or from any other model provider like Azure OpenAI, AWS Bedrock, AWS SageMaker and Anthropic. Our unified approach makes it easy to experiment with and productionize models from any cloud or provider to find the best candidate for your real-time application. You can do A/B testing of different models and monitor model quality on live production data once they are deployed. Model Serving also has pre-deployed models such as Llama2 70B, allowing you to jump-start developing AI applications like retrieval augmented generation (RAG) and provide pay-per-token access or pay-for-provisined compute for throughput guarantees.
- Unified management for all models : Manage all models including custom ML models like PyFunc, scikit-learn and LangChain, foundation models (FMs) on Databricks like Llama 2, MPT and BGE, and foundation models hosted elsewhere like ChatGPT, Claude 2, Cohere and Stable Diffusion. Model Serving makes all models accessible in a unified user interface and API, including models hosted by Databricks, or from another model provider on Azure and AWS.
- Governance built-in : Meet stringent security and governance requirements, because you can enforce proper permissions, monitor model quality, set rate limits, and track lineage across all models whether they are hosted by Databricks or on any other model provider.
- Data-centric models : Accelerate deployments and reduce errors through deep integration with the Data Intelligence Platform. You can easily host various generative AI models, augmented (RAG) or fine-tuned with their enterprise data. Model Serving offers automated lookups, monitoring and governance across the entire AI lifecycle.
- Cost-effective : Serve models as a low-latency API on a highly available serverless ervice with both CPU and GPU support. Effortlessly scale from zero to meet your most critical needs - and back down as requirements change. You can get started quickly with one or more pre-deployed models and pay-erp-token (on demand with no commitments) or pay-for-provisined compute workloads for guaranteed throughput. Databricks will take care of infrastructure management and maintenance costs, so you can focus on delivering business value.
Mosaic AI Training - Train your own LLMs and other generative AI models
- Build custom LLMs trained on your enterprise data with Mosaic AI Training. Custom models are differentiated and tailored to the context of your business and domain, improving the quality of your generative AI applications.
- Efficient and simple : Training large language models is usually complex and difficult and requires extensive expertise. However, Mosaic AI Training lets anyone easily and efficiently train their own custom LLMs by simply pointing to their data sources. Mosaic AI Training handles the rest: scaling to hundreds of GPUs, monitoring and auto-recovery. Training multibillion parameter LLMs can be completed in days, not weeks.
- Cost-effective : Mosaic AI Training is an optimized software stack that makes training LLMs cost-effective. A combination of system-level optimizations, tuned parallelism strategies and model training science results in a proven track record that lowers the cost of training LLMs by up to 10x.
- Effortless scale : A key element to high-performance LLM training is scalability, which requires fast, low-latency networking and access to the highest-performing GPUs. Using Mosaic AI Training automatically gives you access to both NVIDIA InfiniBand networking and NVIDIA H100 Tensor Core GPUs, the highest-performing NVIDIA GPUs, which give unprecedented performance and scalability compared to previous hardware generations. This lets you scale to train large (> 70 billion-parameter) models easily and complete training runs in hours and days.
- Secure and compliant : For most organizations, security is paramount, and they can't afford to have their employees send their data to a third-party API and risk having the data leaked or used to train a public model. Mosaic AI Training ensures that this can never happen, because organizations will build their own LLM where they maintain complete control and ownership over both the data and the model. Everything remains encrypted by default, including traffic and all training data. This ensures you have complete data privacy and full model ownership, meeting any regulatory compliance.
Lakehouse Monitoring - Intelligent data and model monitoring
- Databricks Lakehouse Monitoring allows teams to monitor their entire data pipelines - from data and features to ML models - without additional tools and complexity. Powered by Unity Catalog, it lets users uniquely ensure that their data and AI assets are high quality, accurate and reliable through deep insight into the lineage of their data and AI assets. The single, unified approach to monitoring enabled by lakehouse architecture makes it simple to diagnose errors, perform root cause analysis and find solutions.
- Proactive reporting : PRoactive and simplified detection of anomalies in your data and models, reducing time to market and operational costs incurred due to inefficiencies.
- Unified tooling from data to ML : Gain complete visibility into all your data and models in a matter of minutes. The auto-generated metrics enable you to measure the impact of your data and ML products more effectively right out of the box.
- Automated root cause analysis : Seamlessly debug data and model quality issues by tracking root cause back to the anomalies. Capabilities such as automated root cause analysis mean less time to value and higher efficiencies in your production pipelines.
Managed MLflow - Build better models and generative AI apps
- What is Managed MLflow?
Managed MLflow extends the functionality of MLflow, an open source platform developed by Databricks for building better models and generative AI apps, focusing on enterprise reliability, security and scalability. The latest update to MLflow introduces innovative GenAI and LLMOps features that enhance its capability to manage deploy large language models (LLMs). This expanded LLM support is achieved through new integrations with industry - standard LLM tools OpenAI and Hugging Face Transformers - as well as the MLflow Deployments Server. Additionally, MLflow's integration with LLM framework (e.g., LangChain) enables simplified model development for creating generative AI applications for a variety of use cases, including chatbots, document summarization, text classification, sentiment analysis and beyond.
- Model development : Enhance and expedite machine learning lifecycle management with a standardized framework for production-ready models. Managed MLflow Recipes enable seamless ML project bootstrapping, rapid iteration and large-scale model deployment. Craft applications like chatbots, document summarization, sentiment analysis and classificaiton effortlessly. Easily develop generative AI apps (e.g., chatbots, doc summarization) with MLflow's LLM offerings, which seamlessly integrate with LangChain, Hugging Face and OpenAI.
- Experiment Tracking : Run experiments with any ML library, framework or language, and automatically keep track of parameters, metrics, code and models from each experiment. By using MLflow on Databricks, you can securely share, manage and compare experiment results along with corresponding artifacts and code versions - thanks to built-in integrations with the Databricks workspace and notebooks. You will also be able to evaluate the results of GenAI experiments and improve quality with MLflow evaluation functionality.
- Model management : Use one central place to discover and share ML models, collaborate on moving them from experimentation to online testing and production, integrate with approval and governance workflows and CI/CD pipelines, and monitor ML deployments and their performance. The MLflow Model Registry facilitates sharing of expertise and knowledge, and helps you stay in control.
- Model deployment : Quickly deploy production models for batch inference on Apache Spark TM or as REST APIs using built-in integration with Docker containers, Azure ML or Amazon SageMaker. With Managed MLflow on Databricks, You can operationalize and monitor production models using Databricks jobs scheduler and auto-managed clusters to scale based on the business needs. The latest upgrades to MLflow seamlessly package GenAI applications for deployment. You can now deploy your chatbots and other GenAI applications such as document summarization Sentiment analysis and classification at scale, using Databricks Model Serving.
- Features :
1) MLflow Tracking
2) MLflow Models
3) MLflow Model Registry
4) MLflow Deployments Server
5) MLflow Projects
6) MLflow Recipes
AutoML - Augment experts. Empower citizen data scientists.
Databricks AutoML allows you to quickly generate baseline models and notebooks. ML experts can accelerate their workflow by fast-forwading through the usual trial-and-error and focus on customizations using their domain knowledge, and citizen data scientists can quickly achieve usable results with a low-code approach.
AI Governance
AI Security