Generative AI
What is generative AI ?
Generative AI is a type of AI that can create new content and ideas, including conversations, stories, images, videos, and music. AI technologies attempt to mimic human intelligence in nontraditional computing tasks like image recognition, natural language processing (NLP), and translation. Generative AI is the next step in artificial intelligence. You can train it to learn human language, programming languages, art, chemistry, biology, or any complex subject matter. It reuses training data to solve new problems. For example, it can learn English vocabulary and create a poem from the workds it processes. Your organization can use generative AI for various purposes, like chatbots, media creation, and product devlopment and design.
Foundation Model
What is a Foundation Model?
Trained on massive datasets, foundation models (FMs) are large deep learning neural networks that have changed the way data scientists approach machine learning (ML). Rather than develop artificial intelligence (AI) from scratch, data scientists use a foundation model as a starting point to develop ML models that power new applications more quickly and cost-effectively. The term foundation model was coined by researchers to describe ML models trained on a broad spectrum of generalized and unlabeled data and capable of performing a wide variety of general tasks such as understanding language, generating text and images, and conversing in natural language.
What are examples of foundation models
The number and size of foundation models on the market have grown at a rapid pace. There are now dozens of models available. Here is a list of prominent foundation models released since 2018.
BERT
Released in 2018, Bidirectional Encoder Representaions from Transformers (BERT) was one of the first foundation models. BERT is a bidirectional model that analyzes the context of a complete sequence then makes a prediction. It was trained on a plain text corpus and Wikipedia using 3.3 billion tokens (words) and 340 million parameters. BERT can answer questions, predict sentences, and translate texts.
GPT
The Generative Pre-trained Transformer (GPT) model was developed by OpenAI in 2018. It uses a 12-layer transformer decoder with a self-attention mechanism. ANd it was trained on the BookCorpus dataset, which holds over 11,000 free novels. A notable feature of GPT-1 is the ability to do zero-shot learning.
GPT-2 released in 2019. OpenAI trained it using 1.5 billion parameters (compared to the 117 million parameters used on GPT-1). GPT-3 has a 96-layer neural network and 175 billion parameters and is trained using the 500-billion-word Common Crawl datasets. The popular ChatGPT chatbot is based on GPT-3.5 and GPT-4, the latest version, launched in late 2022 and successfully passed the Uniform Bar Examination with a score of 297 (76%)
Amazon Titan
Amazon Tital FMs are pre-trained on large datasets, making them powerful, general-purpose models.
AI21 Jurassic
Released in 2021, Jurassic-1 is a 76-layer auto regressive language model with 178 billion parameters.
Claude
Claude 2 is Anthropic's state-of-the-art model that excels at thoughtful dialog, content creation, complex reasoning, creativity, and coding.
Cohere
Cohere has two LLMs; one is a generation model with similar capabilites as GPT-3 and the other is a representation model inteded for understanding languages.
Stable diffusion
it is a text-to-image model that can generate realistic-looking, high-definition images. It was released in 2022 and has a diffusion model that uses noising and denosing technologies to learn how to create images.
Bloom
Bloom is a multilingual model with similar architecture to GPT-3.
Hugging Face
Hugging Face is a platform that offers open-source tools for you to build and deploy machine learning models. It acts as a community hub, and developers can share and explore models and datasets. Membership for individuals is free, although paid subscriptions offer higher levels of access. You have public access to nearly 200,000 models and 30,000 datasets.
What are challenges with foundation models?
Large Language Models
Large language models (LLM) are very large deep learning models that are pre-trained on vast amounts of data. The underlying transformer is a set of neural network that consist of an encoder and a decoder with self-attention capabilities. The encoder and decoder extract meanings from a sequence of text and understand the relationships between words and phrases in it.
Transformer LLMs are capable of unsupervised training, although a more precise explanation is that transformers perform self-learning. It is through this process that transformers learn to understand basic grammer, languages, and knowledge.
Unlike earlier recurrent neural networks (RNN) that sequentially process inputs, transformers process entire sequences in parallel. This allows the data scientists to use GPUs for training transformer-based LLMs, significantly reducing the training time.
Transformer neural networks architecture allows the use of very large models, often with hundreds of billions of parameters. Such large-scale models can ingest massive amounts of data, often from the internet, but also from sources such as the Common Crawl, which comprise more than 50 billion web pages, and Wikipedia, which has approximately 57 million pages.
Prompt Engineering
What is prompt engineering?
Prompt engineering is the process where you guide generative artificial intelligence (generative AI) solutions to generate desired outputs. Even though generative AI attempts to mimic humans, it requires detailed instructions to create high-quality and relevant output. In prompt engineering, you choose the most appropriate formats, phrases, words, and symbols that guide the AI to interact with your users more meaningfully. Prompt engineers use creativity plust trial and error to create a collection of input texts, so an application's generative AI works as expected.
What is a prompt?
A prompt is a natural language text that requests the generative AI to perform a specific task.
RAG
What is RAG?
Retrieval-Augmented Generation (RAG) is the process of optimizing the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response. Large Language Models (LLMs) are trained on vast volumns of data and use billions of parameters to generate original output for tasks like answering questions, translating languages, and completing sentences. RAG extends the already powerful capabilities of LLMs to specific domains or an organization's internal knowledge base, all without the need to retrain the model. It is a cost-effective approach to improving LLM output so it remains relevant, accurate, and useful in various contexts.
1. Why is Retrieval-Augmented Generation important?
LLMs are a key artificial intelligence (AI) technology powering intelligent chatbots and other natural language processing (NLP) applications. The goal is to create bots that can answer user questions in various contexts by corss-referencing authoritative knowledge unpredictability in LLM responses. Additionally, LLM training data is static and introduces a cut-off date on the knowledge it has.
Known challenges of LLMs include:
- Presenting false information when it does not have the answer
- Presenting out-of-date or generic information when the user expects a specific, current response.
- Creating a response from non-authoritative sources.
- Creating inaccurate responses due to terminology confusion, wherein different training sourceds use the same terminology to talk about different things.
You can think of the Large Language Model https://aws.amazon.com/what-is/large-language-model/ as an over-enthusiastic new employee who refuses to stay informed with current events but will always answer every question with absolute confidence. Unfortunately, such an attitute can negatively impact user trust and is not something you want your chatbots to emulate
RAG is one approach to solving some of these challenges. It redirects the LLM to retrieve relevant information from authoritative, pre-determined knowledge sources. Organizations have greater control over the generated text output, and users gain insights into how the LLM generates the response.
2. What are the benefits of Retrieval Augmented Generation.
RAG technology brings several benefits to an organizaiton's generative AI efforts. https://aws.amazon.com/what-is/generative-ai/
Cost-effective implementation
Chatbot development typically begins using a foundation model. Foundation models (FMs) are API-accessible LLMs trained on a broad spectrum of generalized and unlabeld data. The computational and financial costs of retraining FMs for organization or domain-specific information are high. RAG is a more cost-effective approach to introducing new data to the LLM. it makes generative artificial intelligence (generative AI) technology more broadly accessible and usable.
Current information
Even if the original training data sources for an LLM are suitable for your needs, it is challenging to maintain relevancy. RAG allows developers to provide the latest research, statistics, or news to the generative models. They can use RAG to connect the LLM directly to live social media feeds, news sites, or other frequently-updated information sources. The LLM can then provide the latest information to the users.
Enhanced user trust
RAG allows the LLM to present accurate information with source attribution. The output can include citations or references to sources. USers can also look up source documents themselves if they require further clarification or more detail. This can increase trust and confidenced in your generative AI solution.
More developer control
With RAG, developers can test and improve their chat applications more efficiently. They can control and change the LLM's information sources to adapt to changing requirements or cross-functional usage. Developers can also restrict sensitive information retrieval to different authorization levels and ensure the LLM generates appropriate responses. In addition, they can also troubleshoot and make fixes if the LLM references incorrect information sources for specific questions. Organizations can implement generative AI technology more confidently for a broader range of applications.
3. How does Retrieval-Augmented Generation work?
Without RAG, the LLM takes the user input and creates a response based on information it was trained on - or what it already knows. With RAG, an information retrieval component is introduced that utilizes the user input to first pull information from a new data source. The user query and the relevant information are both given to the LLM. The LLM uses the new knowledge and its training data to create better responses. The following sections provide an overview of the process.
Create external data
The new data outside of the LLM's original trainig data set is called external data. It can com from multiple data sources, such as a APIs, databases, or document repositories. The data may exist in various formats like files, database records, or long-form text. Another AI technique, called embedding language models, converts data into numerical representations and stores it in a vector database. This process creates a knowledge library that the generative AI models can understand.
Retrieve relevant information
The next step is to perform a relevancy search. The user query is converted to a vector representation and matched with the vector databases. For example, consider a smart chatbot that can ansdwer human resource questions for an organization. IF an employee searches, "How much annual leave do I have?" the system will retrieve annual leave policy documents alongside the individual employee's past leave record. These specific documents will be returned because they are highly-relevant to what the employee has input. The relevancy was calculated and established using mathematical vector calculations and representations.
Augment the LLM prompt
Next, the RAG model augments the user input (or prompts) by adding the relevant retrieved data in context. This step uses prompt engineering techniques to communicate effectvely with the LLM. The augmented prompt allows the large language models to generate an accurate answer to user queries.
Update external data
The next question may be what if the external data become stale? To maintain current information for retrieval, asynchronously update the documents and update embedding representation of the documents. You can do this through automated real-time processes or periodic batch processing. This is a common challenge in data analytics - different data-science approaches to change management can be used
The following diagram shows the conceptual flow of using RAG with LLMs

What is the difference between Retrieval-Augmented Generation and semantic search ?
Semantic search enhances RAG results for organizations wanting to add vast external knowledge sources to their LLM applications. Moder enterprises store vast amounts of information like manuals, FAQs, research reports, customer service guides, and human resource document repositories across various systems. Context retreival is challenging at scale and consequently lowers generative output quality.
Semantic search technologies can scan large databases of disparate information and retrieve data more accurately. For example, they can answer questions such as "How much was spent on machinery repairs last year?" by mapping the question to the relevant documents and returning specific text instead of search results. Developers can then use that answer to provide more context to the LLM.
Conventional or keyword search solutions in RAG produce limited results for knowledge-intensive tasks. Developers must also deal with word embeddings, document chunking, and other complexities as they manually prepare their data. In contrast, semantic search technologies do all the work of knowledge base preparation so developers don't have to. They also generate semantically relevant passages and token words orderd by relevance to maximize the quality of the RAG payload.
How can AWS support your Retrieval-Augmented Generation requirements?
Amazon Bedrock is a fully-managed service that offers a choice of high-performing foundation models - along with a broa dset of capabilites - to build generative AI applications while simplifying development and maintaining privacy and security. With knowledge bases for Amazon Bedrock, you can connect FMs to your data sources for RAG in just a few clicks. Vector conversions, retrievals, and improved outout generation are all handled automatically.
For organizations managing their own RAG, Amazon Kendra is a highly accurate enterprise search service powered by machine learning. It provides an optimized Kendra Retrieve API that you can use with Amazon Kendra's high-accuracy semantic ranker as an enterprise retriever for your RAG workflows. For example, with the Retrieve API, you can :
- Retrieve up to 100 semantically-relevant passages of up to 200 token words each, ordered by relevance.
- Use pre-built connectors to popular data technologies like Amazon Simple Storage Service, SharePoint, Confluence, and other websites.
- Support a wide range of document formats such as HTML, Word, PowerPoint, PDF, Excel, and text files.
- Filter responses based on those documents that the end-user permissions allow
Amazon also offers options for organizations who want to build more custom generative AI solutions. Amazon SageMaker JumpStart is a ML hub with FMs, built-in algorithms, and prebuilt ML solutions that you can deploy with just a few clicks. You can spped up RAG implementation by referring to existing SageMaker notebooks and code examples.
Get started with Retrieval-Augmented Generation on AWS by creating a free account today.
LangChain
What is LangChain?
LangChain is an open source framework for building applications based on large language models (LLMs). LLMs are large deep-learning models pre-trained on large amounts of data that can generate responses to user queries—for example, answering questions or creating images from text-based prompts. LangChain provides tools and abstractions to improve the customization, accuracy, and relevancy of the information the models generate. For example, developers can use LangChain components to build new prompt chains or customize existing templates. LangChain also includes components that allow LLMs to access new data sets without retraining.
Why is LangChain important?
LLMs excel at responding to prompts in a general context, but struggle in a specific domain they were never trained on. Prompts are queries people use to seek responses from an LLM. For example, an LLM can provide an answer to how much a computer costs by providing an estimate. However, it can't list the price of a specific computer model that your company sells.
To do that, Machine learning engineers must integrate the LLM with the organization's internal data sources and apply prompt engineering - a practice where a data scientist refines inputs to a generative model with a specific structure and context.
LangChain streamlines intermediate steps to develop such data-responsive applications, making prompt engineering more efficient. IT is designed to develop diverse applications powerd by language models more effortlessly, including chatbots, question-answering, content generation, summrizers, and more.
The following sections describe benefits of LangChain
1. Repurpose language models
2. Simplify AI development
3. Developer support
How dues LangChain work?
With LangChain, developers can adapt a language model flexibly to specific business contexts by designating steps required to produce the desired outcome.
Chains
Chains are the fundamental principle that holds various AI components in LangChain to provide context-aware responses. A chain is a series of automated actions from the user's query to the model's output. For example, developers can use a chain for :
- connecting to different data sources.
- generating unique content.
- translating multiple languages.
- answering user queries.
Links
To use LangChain, developers install the framework in python with the following command
pip install langchain
Developers then use the chain buidling blocks or LangChain Expression Language (LCEL) to compose chains with simple programming commands. The chain() function passes a link's arguments to the libraries. the execute() command retrieves the results. Developers can pass the current link result to the following link or return it as the final output.
Below is an example of a chatbot chain function that returns product details in multiple languages.
chain([
retrieve_data_from_product_database().
send_data_to_language_model().
format_output_in_a_list().
translate_output_in_target_language()
])

What are the core components of LangChain?
Using LangChain, software teams can build context-aware language model systems with the following modules.
- LLM interface LangChain provides APIs with which developers can connect and query LLMs from their code. Developers can interface with public and proprietary models like GPT, Bart, and PaLM with LangChain by maing simple API calls instead of writing complex code.
- Prompt templates Prompt templates are pre-built structures developers use to consistently and precisely format queries for AI models. Developers can create a prompt template for chatbot applications, few-shot learning or deliver specific instructions to the language models. Moreover, they can reuse the templates across different applications and language models.
- Agents Developers use tools and libraries that LangChain provides to compose and customize existing chains for complex applications. An agent is a special chain that prompts the language model to decide the best sequence in response to a query. When using an agent, developers provide the user's input, available tools, and possible intermedite steps to achieve the desired results. Then, the language model returns a viable sequence of actions the application can take.
- Retrieval modules LangChain enables the architecting of RAG systems with numerous tools to transform, store, search, and retrieve information that refine language model responses. Developers can create semantic representations of information with word embeddings and store them in local or cloud vector databases.
- Memory Some conversational language model applications refine their responses with informatino recalled from past interactions. LangChain allows developers to include memory capabilities in their systems. It supports:
1) simple memory systems that recall the most recent conversations.
2) complex memory structure that analyze historical messages to return the most relevant results.
- Callbacks Callbacks are codes that developers place in their applicaitons to log, monitor, and stream specific events in LangChain operations. For example, developers can track when a chain was first called and errors encountered with callbacks.
How can AWS help with your LangChain requirements?
- Amazon Bedrock
- Amazon Kendra
- Amazon SageMaker Jumpstart
Vector Database
What is a Vector database?
Information comes in many forms. Some information is unstructured - like text documents, rich media, and audio - and some is structured - like application logs, tables, and graphs. Innovations in artificial intelligence and machine learning (AI/ML) have allowed us to create a type of ML models - embedding models. Embeddings encode all types of data into vectors that capture the meaning and context of an asset. THis allows us to find similar assets by searching for neighboring data pints. Vector search methods allow unique experiences like taking a photograph with your smartphone and searching for similar images.
Vector databses provide the ability to store and retrieve vectors as high-dimensional points. They add additional capabilites for efficient and fast lookup of nearest-neighbors in the N-dimensional space. They are typically powered by k-nearest neighbor (k-NN) indexes and built with algorithms like the Hierarchical Navigable Small World (HNSW) and Inverted File Index (IVF) algorithms. Vector databases provide additional capabilities like data management, fault tolerance, authentication and access control, and a query engine.
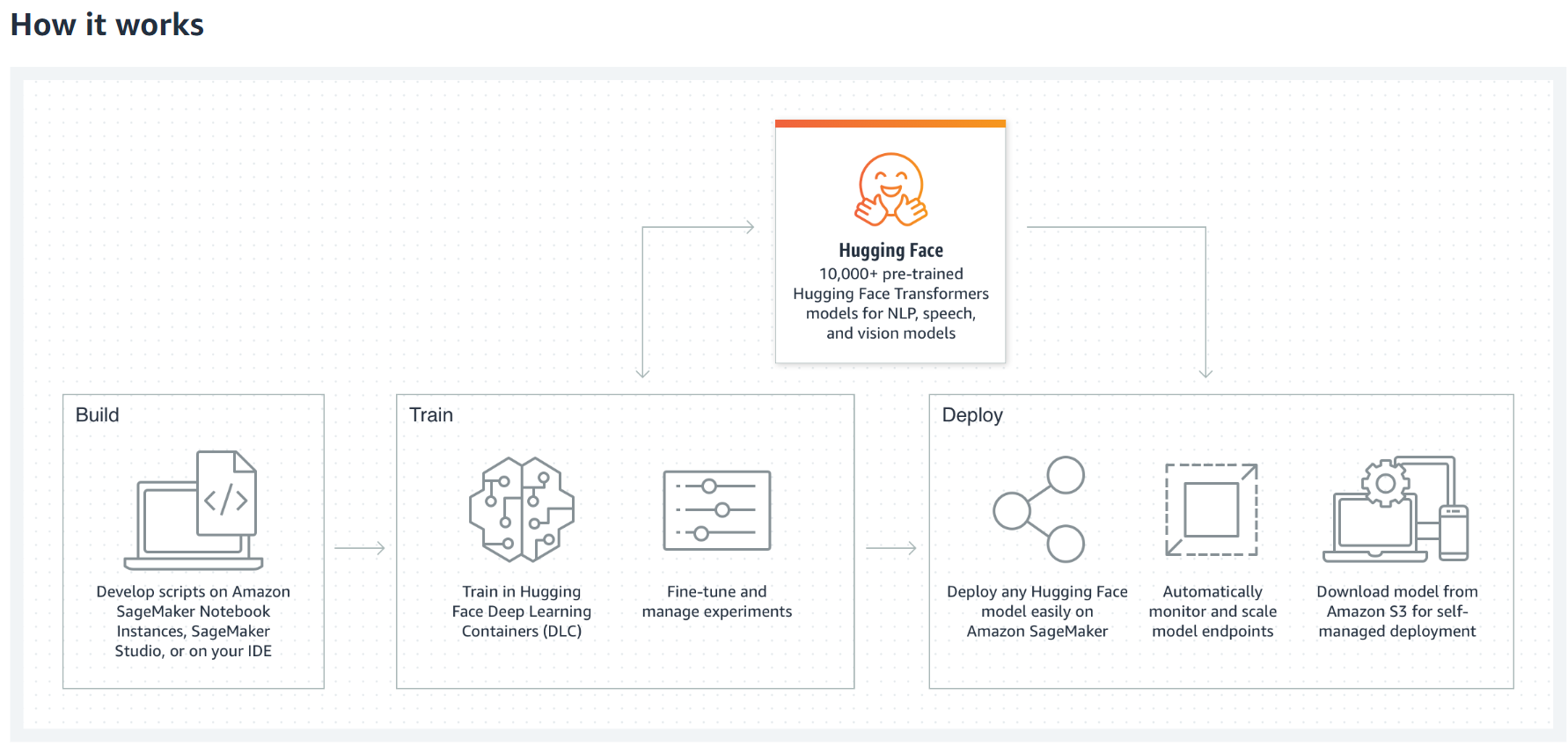
Hugging Face on Amazon SageMaker
Train and deploy Hugging Face models in minutes
WIth Hugging Face on Amazon SageMaker, you can deploy and fine-tune pre-trained models from Hugging Face reducing the time it takes to set up and use natural language processing (NLP) models from weeks to minutes.
NLP refers to machine learning (ML) algorithms that help computers understand human language. They help with translation, intelligent search, text analysis, and more. However, NLP models can be large and complex (sometimes consisting of hundreds of millions of model parameters), and training and optimizing them requires time, resources, and skill.
AWS collaborated with Hugging Face to create Hugging Face AWS Deep Learning Containers (DLCs), which provide data scientists and ML developers a fully manageed experience for building, training, and deploying state-of-the-art NLP models on Amazon SageMaker.
Reference
Generative AI
https://aws.amazon.com/what-is/generative-ai/
Foundation Model
https://aws.amazon.com/what-is/foundation-models/
Large Language Model (LLMs)
https://aws.amazon.com/what-is/large-language-model/
Prompt Engineering
https://aws.amazon.com/ko/what-is/prompt-engineering/
Retrieval Augmented Generation (RAG)
https://aws.amazon.com/what-is/retrieval-augmented-generation/?nc1=h_ls
LangChain
https://aws.amazon.com/what-is/langchain/?nc1=h_ls
Vector Database
https://aws.amazon.com/ko/what-is/vector-databases/
Hugging Face
https://aws.amazon.com/ko/machine-learning/hugging-face/
'Generative AI' 카테고리의 다른 글
| [Databricks][Documentation] Generative AI & LLMs (0) | 2024.04.28 |
|---|---|
| [FastCampus] GenAI / LLM Lecture (0) | 2024.04.28 |
| [Databricks] The Big Book of Generative AI (1) | 2024.04.20 |
| [Databricks] Generative AI Engineering Pathway (0) | 2024.04.19 |
| Generative AI on Artefact (0) | 2024.04.18 |



